


The Disaster Nobody Thought Would Happen (Until It Did)
The Swiss Cheese Model shows why failures stack up and how to stop them in time.

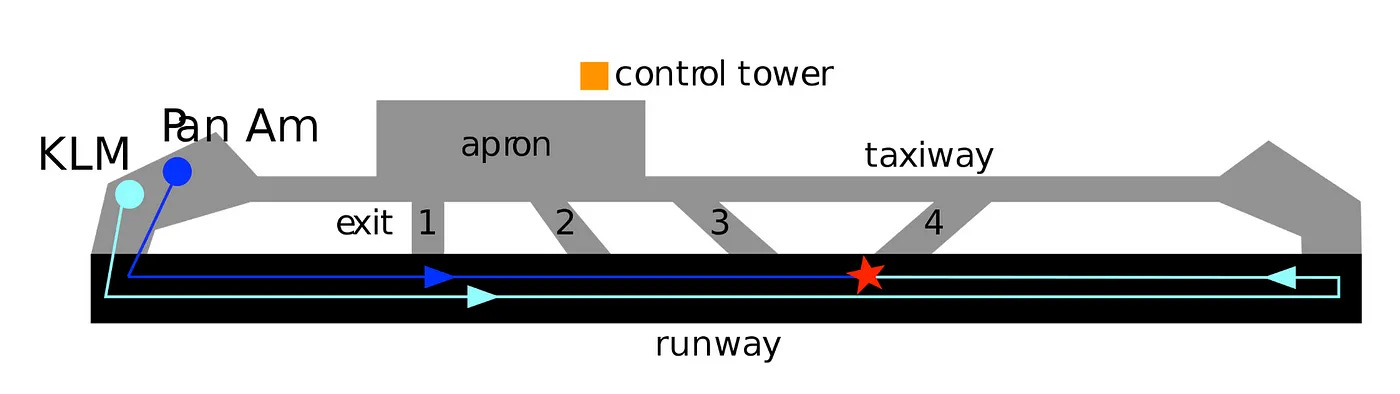
March 27, 1977. A thick fog swallowed Tenerife Airport.
Two Boeing 747s, Pan Am 1736 and KLM 4805, prepared for takeoff.
The KLM captain advanced the throttles.
On the same runway, Pan Am was still taxiing.
A radio transmission crackled.
“We’re still taxiing down the runway, Clipper 1736!”
Seconds later, disaster.
The two planes collided at full speed. 583 lives were lost.
It remains the deadliest aviation disaster in history1.
But here’s the kicker: neither plane was supposed to be there.

Tenerife: A Disaster Years in the Making?
Both flights had been rerouted due to a terrorist threat at the nearby Gran Canaria Airport, forcing Tenerife, a small and understaffed airfield2, to handle an overflow of large aircraft.
{kind=link}
Then, more cracks appeared3:
Dense fog reduced visibility to near-zero. Pan Am missed a turn (3) down the runway.
No ground radar meant air traffic controllers had no way to see aircraft positions.
The KLM captain, eager to depart, misinterpreted clearance and began takeoff, unaware Pan Am was still on the runway.
Radio interference blocked the warning from Pan Am.
By the time the pilots saw each other through the thick fog, it was too late.
But was this really just bad luck?

Why Do Disasters Happen? The Swiss Cheese Model Explains.
Most people assume failures happen because of one big mistake. But that’s almost never true.
Instead, failures unfold like a series of small cracks lining up perfectly.
Each one insignificant on its own, but together, catastrophic.
This is the Swiss Cheese Model.

Picture stacking slices of Swiss cheese. Each one is a safeguard–rules, processes, defences. But every slice has holes.
Most of the time, the layers cover for each other. A mistake here gets caught by a safeguard there.
But if the holes in multiple layers line up just right, the system fails.
🚨 Quick sidebar: Enjoying what you’re reading? Sign up for my newsletter to get similar actionable insights delivered to your inbox.
Pssttt… you will also get a copy of my ebook, Framework for Thoughts, when you sign up!
Tenerife wasn’t the result of one bad decision. It was the culmination.
💣 The bomb threat at Gran Canaria was the first crack, though external, forcing both flights to an unprepared airport.
🌫️ Poor weather made visibility nearly impossible.
📡 No ground radar meant ATC couldn’t monitor aircraft positions.
🔊 Miscommunication and radio interference prevented crucial corrections.
👨✈️ Authority bias stopped KLM’s first officer and flight engineer from pressing further on the captain’s premature takeoff4.
Each of these alone? A manageable risk. But together? Disaster.
I read about the Tenerife disaster in Morgan Housel’s Same As Ever. Btw, you can find my favourite books here. In the book, Housel also wrote:
Big risks are easy to overlook because they’re just a chain reaction of small events, each of which is easy to shrug off.
So people always underestimate the odds of big risks.
This chain reaction doesn’t just happen in aviation. It plays out everywhere in our real life.
Small Mistakes Don’t Stay Small. Here’s Why.
A bad morning isn’t just about waking up late. It’s the alarm that didn’t go off, the spilled coffee on your shirt, the unexpected traffic, and the urgent email waiting for you, all stacking up until you’re wondering if the universe is out to get you.
A company collapse isn’t about one bad decision. It’s often a mix of cash flow problems, leadership issues, and market downturns converging at the worst time.
Or a cyberattack doesn’t succeed because of one weak password. It’s usually a combination of outdated software, poor training, and a delayed security response that opens the door.
The danger isn’t in any single failure. It’s in their ability to compound into something bigger than the sum of their parts5.
Basically, when all the holes line up, disaster walks right in like…

How to Stop Tiny Failures from Turning Into Disasters
Since risk isn’t a single point of failure, the best way to prevent disaster is to design layers that don’t rely on luck.
⛓️💥 Assume Risks Are Connected (Because They Are)
Small risks don’t stay small when they stack up.
In Tenerife, nobody accounted for how fog + no ground radar + communication failures + authority bias could combine.
Instead of just fixing individual risks, ask: How might they interact?
Each was a known issue, probably considered low risk. But because they weren’t treated as interconnected risks, they weren’t addressed holistically becoming high impact.
😌 The Only Way to Prevent Disaster? Assume It’s Coming.
The smartest way to prevent failure isn’t by fixing every flaw. It’s by designing systems that can survive failure.
The reason New Zealand managed COVID better than most was that they didn’t rely on a single defence mechanism.
Instead of plugging every hole, build layers that don’t depend on each other. If one fails, the others should still stand.

💪🏼 Strengthen Weak Links
A chain is only as strong as its weakest link. So, fix the weak parts. Don’t just add more layers.
After Tenerife, the aviation industry didn’t just add more checklists but they introduced Crew Resource Management (CRM), training pilots to challenge authority when necessary6.
A security system with multiple checkpoints is useless if all the passwords are "123456."
So, more layers are good but if every layer is weak, failure is inevitable. Strengthen the foundation, not just the walls.

🙅♂️ Build Buffers (Because Things Will Go Wrong)
When failure compounds, the best defence isn’t perfection. It’s margin. Add breathing room. Add margin of safety.
If you’re planning a major project, assume delays and build extra time.
If you’re investing, don’t put yourself in a position where one bad market day wipes you out.
If you’re traveling, don’t cut it so close that a single delay means missing your flight.
Disaster happens when there’s no room for error. A little extra space, turns major failures into minor setbacks.

Summary:
Big failures don’t happen all at once. They happen when small, manageable risks go unnoticed until they align perfectly.
Increase your layers, distribute them, and strengthen them.
Expect small things to go wrong, analyse the failures by stacking them.
Accidents aren’t sudden. They gather slowly, one missed warning, one overlooked flaw, until all the cracks align, and the system fails.
Until next time,
Tapan (Connect with me by replying to this email)
Ostriches Don’t Actually Bury Their Heads—But We Do

Not all failures happen because we don’t see the risks, sometimes, we see them and look away. This article on the Ostrich effect explains why.
Thank you for reading! 🙏🏽 Help me reach my goal of 2,300 readers in 2025 by sharing this post with friends, family, and colleagues! ♥️
As an Amazon Associate, tapandesai.susbtack.com earns commission from qualifying purchases.
The September 11 attacks, which killed 2,996 people, are deadlier. However, they are not counted as aviation accidents. Instead, they are counted as terrorist attacks (source).
Ebert, John David (2012). The Age of Catastrophe: Disaster and Humanity in Modern Times (Pg. 40)
All details have been summarised from "ALPA report on the crash".
The Captain for the KLM flight Chief Flight Instructor for KLM with his photo being featured in the KLM magazine in 1977. So, was highly respected with the staff. The First Officer and Flight Engineer flagged that they didn’t have the clearance but were disregarded.
But the Swiss cheese model has a blindspot. The Swiss Cheese Model shows how failures align but it doesn’t ask why the same cracks keep appearing. For example, a pilot who misses a small miscommunication might be experiencing fatigue or working in an airline with poor training standards across the board.
Cooper, G. E., White, M. D., & Lauber, J. K. (Eds.) 1980. "Resource management on the flightdeck", Proceedings of a NASA/Industry Workshop (NASA CP-2120).
Reminds me of physics lesson “strength of chain is strength of weakest link”
Reminded me of the concept of "triple safe" for aircraft, system be able to withstand 3 time more stress than expected and critical ones should have triple redundancy!
Of course as you explained, even with that there can be series of failure (usually involving human error) that lead to catastrophic outcomes...